AI 中的 Python 核心编程基础 Ⅰ
- 18 分钟前Python的程序的执行过程
高级语言程序的生命周期是从高级语言源代码开始的,程序在执行时需要被将高级语言代码翻译成机器语言代码。翻译的形式一般有三种:编译(C/C++)、解释(Ruby)、先编译后解释(Java/Python)。
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。
解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行。
Java首先是javac hello.java通过编译器编译成字节码文件,然后在运行时通过解释器给解释成机器文件。所以我们说Java是一种先编译后解释的语言。其实 Python 也一样,当我们执行python hello.py时,他也一样执行了这么一个过程,所以我们应该这样来描述Python,Python是一门先编译后解释的语言。
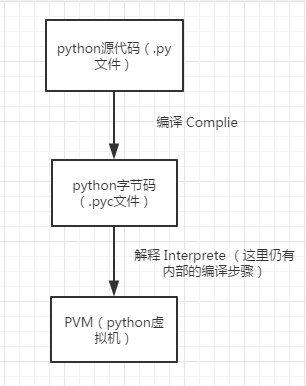
- PyCodeObject:Python程序运行时,用来保存Python编译器真正编译成的结果,位于内存中;
- pyc文件:当程序运行结束Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
增强版解释器:IPython
- 代码补全:tab
- 查看信息:?
- 与命令行交互:!
- 魔法命令:
%magic - 类 MATLAB 的科学计算模式:-pylab
Jupyter Notebook
- 可以轻松将一系列运行结果保存成文档,分享和保存
- 基于web可以使用远程的后端计算引擎
REPL-DD(交互式命令行驱动开发)
- 命令行模式与脚本模式
- 初学Python的最佳编程模式:REPL
解释器默认搜索路径
Python解释器在 import 时,是否导包成功取决于 Python 是否找得到相应的模块。
Python解释器先在sys.path中按顺序查找
print()
>>> print("Hello")
Hello
>>> print(300)
300
>>> print(100 + 200) # 小括号中当作表达式,会进行运算操作直到只有一个操作数
300
>>> print('100 + 200 =', 100 + 200) # 注意空格哦
100 + 200 = 300
Input()
通过外设向Python解释器输入信息。
>>> name = input()
SIGAI
>>> print(name)
SIGAI
>>> name = input('please enter your name: ')
please enter your name: sigai
>>> print(name)
sigai
Python细节
- 大小写敏感
- 缩进:Tab vs 4个空格,不同的解释器会以不同的方式解释 Tab,有的是 4 个空格,有的是 2 个空格。
数据类型
- 整数:可处理任意大小的整数。
- 浮点数:由于内部存储方式不同,整数计算永远精确,浮点数计算则不是。
- 字符串:单引号、双引号或三引号括起来的任意文本。
- 布尔值:
True or False:可进行and or not运算 - 空值:None, 不等于 0
常量
编码规范:通常用全部大写的变量名表示常量。
基本运算
>>> 1 + 1
2
>>> 2 - 1
1
>>> 2 * 3
6
>>> 3 / 2 # Python 除法可以得到浮点数值
1.5
>>> 2 ** 3 #幂
8
>>> 3 // 2 #向下取整
1
>>> 3 % 2
1
>>> 3.0 // 2.0
1.0
>>> -5 // 3
-2
>>> -6 // 3
-2
>>> -7 // 3
-3
变量
- Python 是动态类型语言,变量可以是任意数据类型
- 使用变量,必须先给变量赋值。
Python变量指向一个对象,而对象有可变与不可变之分。
可变类型与不可变类型
如果给变量赋值的是可变类型,变量的地址不变;如果给变量赋值的是不可变类型,变量的地址发生改变,会指向不可变类型的地址。
>>> a = "SIGAI"
>>> id(a)
140182492168632
>>> a = "sigai"
>>> id(a)
140182492168688
>>> a = ["sigai_1", "sigai_2"]
>>> id(a)
140182492190088
>>> a.append("sigai_3")
>>> a
['sigai_1', 'sigai_2', 'sigai_3']
>>> id(a)
140182492190088
可变对象与不可变对象
>>> L = ['sigai_2', 'sigai_3', 'sigai_1']
>>> print(sorted(L)) #sorted 仅仅将参数复制了一份到内存,改变的是 L 的备份
['sigai_1', 'sigai_2', 'sigai_3']
>>> print(L)
['sigai_2', 'sigai_3', 'sigai_1']
>>> L.sort() # 改变的是 L 本身
>>> print(L)
['sigai_1', 'sigai_2', 'sigai_3']
>>> s = 'sigai'
>>> print(s.replace('s', 'S'))
Sigai
>>> print(s)
sigai
务必搞清楚,你改变的是对象本身,还是仅得到了⼀个中间结果 。
- 变量是无类型的,对象是有类型的;
- 对象是内存中存储数据的实体,变量则是指向对象的指针。
引用与拷贝
可变类型对象的赋值,传递的是引⽤,类似于C语⾔中的指针;
如果不想传递引用,需要使用拷贝的方式。
List 和 Tuple
List 是一个可变有序集合,Tuple 是初始化后不可修改的 List。
切片:充分发挥List的有序特性
取出前三个字符串组成新的列表,就可以使用切片功能来完成:
>>> L = ['tensorflow', 'torch', 'caffe', 'mxnet', 'keras']
>>> newL = L[:3]
>>> newL
['tensorflow', 'torch', 'caffe']
切片功能的三个参数:起始位置:终止位置:步长(只有第一个 :是必须有的)。
当 :前没有数字时,默认补 0。
>>> L = list(range(1,11))
>>> L
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> L[:5]
[1, 2, 3, 4, 5]
>>> L[:12]
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> L[:-1]
[1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> L[:-3]
[1, 2, 3, 4, 5, 6, 7]
>>> L[:-15]
[]
>>> L[:0]
[]
0 是第一个;-1 是最后一个。
从起始位置到终止位置,包含起始位置,不包含终止位置。
超出范围时不会报错。
步长也可以是负数。
>>> L[2:5]
[3, 4, 5]
>>> L[2:-1]
[3, 4, 5, 6, 7, 8, 9]
>>> L[1:5:3]
[2, 5]
>>> L[-1:0:-1]
[10, 9, 8, 7, 6, 5, 4, 3, 2]
>>> L[-1::-1]
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
>>> L[::-1]
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
>>> L[::]
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> L[:]
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
多重 List 的浅拷贝与深拷贝
import copy
a = [[1, 2, 3], [4, 5, 6]]
# 将 a 的引用赋值给 b,仅是重命名而已
b = a
c = copy.copy(a)
d = copy.deepcopy(a)
a.append(7)
a[1][2] = 10
print('原数组: ', a)
print('引⽤赋值: ', b)
print('浅拷⻉: ', c)
print('深拷⻉: ', d)
# 执行结果:
原数组: [[1, 2, 3], [4, 5, 10], 7]
引⽤赋值: [[1, 2, 3], [4, 5, 10], 7]
# 浅拷贝append语句无效
浅拷⻉: [[1, 2, 3], [4, 5, 10]]
# 深拷贝 赋值语句和 append语句失效
深拷⻉: [[1, 2, 3], [4, 5, 6]]
-
浅拷贝:将 List 中的每个 List 元素的起始地址都拷贝了一份给 c
-
深拷贝:将所有的可变对象变为不可变对象再拷贝
序列的加法、乘法、内置方法
- 同类型的序列可以相加
- 序列可以和整数相乘,从而快速创建包含重复元素的序列
- 常见内置方法
- in
- len
- max
- min
List 和 str 的相互转换
>>> s
'sigai'
# list(str) 可之间转为 List
>>> l = list(s)
>>> l
['s', 'i', 'g', 'a', 'i']
# ''.join(List) 将 List 转为 str
>>> s_from_l = ''.join(l)
>>> s_from_l
'sigai'
List 的元素或切片的赋值与删除
>>> L = list(range(5))
>>> L
[0, 1, 2, 3, 4]
>>> L[2], L[4] = L[4], L[2]
>>> L
[0, 1, 4, 3, 2]
>>> del L[2]
>>> L
[0, 1, 3, 2]
# 切片的赋值和删除、还可以用作插入
>>> L = [1,5]
# 在下标为 1 的位置插入 2,3,4
>>> L[1:1] = list(range(2,5))
>>> L
[1, 2, 3, 4, 5]
# 删除下标为2,3的元素
>>> L[2:4] = []
>>> L
[1, 2, 5]
>>> del L[1:]
>>> L
[1]
List 的排序
- sorted() 函数排序后返回,原列表不变;
- L.sort() 就地排序,直接修改原列表
- L.sort() 是对象的⽅法,不是函数,没有返回值
Tuple 中的括号歧义
>>> T = (1) # 小括号中当做表达式进行运算,输出了数字 1
>>> print(T)
1
>>> T = (1, 2)
>>> print(T)
(1, 2)
>>> T = (1,) # 只有一个元素的Tuple在定义时必须添加 , 来消除歧义
>>> print(T)
(1,)
Tuple 中的 List 依旧可变
>>> T = ('sigai', [1, 2, 3])
>>> print(T)
('sigai', [1, 2, 3])
>>> T[1].append(4)
>>> print(T)
('sigai', [1, 2, 3, 4])
Dict 和 Set
- Dict 是 Python中可变的key-value形式的数据结构, 查找速度极快。
- 使用的是⽤空间换时间的策略,消耗内存⼤。
- 内部存放顺序与放⼊key的顺序⽆关。
- key必须是不可变对象 。
- Set : Dict 中 key 的集合。
- 由于key必须hashable,也就是说key是唯⼀的,因此Set中⽆重复的Key 。
Python字符编码
- ASCII 编码省空间但容易出现乱码;
- Unicode 同一了各种语言的编码,但可能出现大量空间冗余;
- UTF-8:可变长的 Unicode 编码;
- ASCII 可被认为是 UTF-8的一部分。
常见工作模式
- 内存中:Unicode
- 存储和传输时:UTF-8
存储和传输时考虑带宽等问题,就需要采用 UTF-8传输,而在内存中处理时,将 UTF-8 读入内存转 UNICODE 处理,处理完成后再转为 UTF-8 进行传输。
Python中的字符串
内存中默认的字符串是str类型,以Unicode编码 存储或传输时⽤以字节为单位的bytes类型。
>>> print('Inger开心')
Inger开心
>>> type('Inger开心')
<class 'str'>
>>> print(b'Inger开心')
File "<stdin>", line 1
SyntaxError: bytes can only contain ASCII literal characters.
>>> print(b'Inger')
b'Inger'
>>> type(b'Inger')
<class 'bytes'>
- 纯英文可用 ASCII 将 str 编码为 bytes
- 含有中文则可用 UTF-8 将 str 编码为 bytes
- 从网络或磁盘上读取的字节流为 bytes
条件判断
Bool 变量的基本判断规则和方法
>>> not True
False
>>> not False
True
>>> True and False
False
>>> True or False
True
>>> True == False
False
>>> True != False
True
>>> True > False
True
>>> True >= False
True
>>> True < False
False
>>> True <= False
False
>>> True is False
False
>>> True is True
True
>>> False < True <= True
True
>>> False < True < True
False
数字的基本判断规则与方法
>>> 0 and 2
0
>>> 0 or -2
-2
>>> not 2
False
>>> not 0
True
>>> not -1
False
>>> -2 < 3 < 2
False
>>> 0 == False
True
>>> 1 == True
True
>>> 2 == True
False
>>> 0 is False
False
>>> 1 is True
False
逻辑判断小坑
==!=><>=<=:计算⽤数值,结果⽤布尔;not:计算⽤布尔,结果⽤布尔;is:不计算,只判断;- 链式判断⼤⼩关系 :结果与数学上保持⼀致;
and:从左向右找 0 或者 False ,找到则⽴即返回,未找到则返回最后⼀个;- 假如有 1000 个数,从头到尾找 0 或 False,找到立刻返回,否则返回最后一个数字。
or:从左向右找 ⾮0数字 或者 True ,找到则⽴即返回,未找到则返回最后⼀个。
>>> 1 and 2 and 3 # 无0 返回最后一个数
3
>>> 1 and True and 3
3
>>> 1 and 2 and True
True
>>> 1 and 0 and 3 # 找到 0 或 False 立即返回
0
>>> 1 and False and 3
False
>>> 0 and False and 3
0
>>> False and 0 and 3
False
>>> 3 or 2 or 1 #找到第一个非 0 数字或 True 立即返回
3
>>> 0 or 2 or 1
2
>>> False or 2 or 0
2
>>> 0 or False or -3
-3
>>> 0 or False or 0
0
>>> 0 or False or False
False
函数
内置函数
>>> abs(-2)
2
>>> abs(3)
3
>>> int('-2')
-2
>>> str(-2)
'-2'
>>> float(-2)
-2.0
>>> int(-2.0)
-2
>>> bool(-2)
True
>>> int(True)
1
>>> max([5,3,6,4,7])
7
>>> min([5,3,6,4,7])
3
>>> my_func = max
>>> my_func([5,3,6,4,7])
7
定义函数
# Python函数可返回多个返回值
def my_max(a, b):
if a > b:
return a, b
else :
return b, a
# 传入多个参数
def calc_sum(*numbers):
sum = 0
for n in numbers:
sum += n
return sum
# 程序入口
if __name__ == '__main__':
# 使用assert来判断函数运行结果
assert my_max(1,2) == (2, 1)
assert my_max(4,3) == (4, 3)
assert calc_sum(1, 3, 5) == 9
入门小坑:默认参数的记忆性
默认参数在函数定义时已被计算并冻结,因此默认参数一般指向不变对象。
>>> def add_sigai(L = []):
... L.append('sigai')
... return L
...
>>> add_sigai([1,2,3])
[1, 2, 3, 'sigai']
# 将 L 作为参数继续执行 add_sigai()
>>> add_sigai()
['sigai']
>>> add_sigai()
['sigai', 'sigai']
>>> add_sigai()
['sigai', 'sigai', 'sigai']
面向对象
# Python中的类都继承自 object
class Student(object):
# 类的默认构造函数
def __init__(self, name, score=-1):
self.__name = name
self.__score = score
self.say_hi()
def name(self):
return self.__name
def say_hi(self):
if self.__score < 0:
print("{}: Hi, my name is {}. I'm a new student.".format(self.__name, self.__name))
else:
print("{}: Hi, my name is {}. My score is {}.".format(self.__name, self.__name, self.__score))
def get_score(self, teacher, score):
self.score = score
print("{}: teacher {} just gave me a {}".format(self.__name, teacher, score))
if __name__ == '__main__':
studentA = Student("A")
Python代码的组织 —— 模块
- 包 -> 模块 -> 类或功能函数
- 每个包里面都含有一个
__init__.py文件,而且必须存在,⽤以区分普通⽬录还是包 - 创建包或者模块的时候,不可与系统⾃带的包或者模块重名
# 第一行用来说明自己模块的功能
'first module'
# 作者
__author__ = 'inger'
# 导包
import sys
# 模块正文
def say_hi():
args = sys.argv
if len(args)==1:
print('Welcome to SIGAI online programming platform!')
elif len(args)==2:
print('Hi, %s, Welcome to SIGAI online programming platform!!' %
args[1])
else:
print('Too many arguments!')
if __name__ == '__main__':
say_hi()

